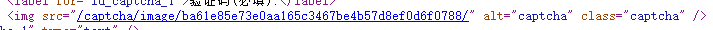昨天偶然间发现了一个爬虫的闯关网站,就赶紧来用它练一练爬虫,今天总算是将五个关卡都通关了,其中也碰到不少坑,通过百度借鉴别人的思路代码也都慢慢解决了,学到了很多,下面就附上五个关卡的思路和代码
Pass-1 网址:http://www.heibanke.com/lesson/crawler_ex00/
首先页面给的提示是要我们在网址后面输入数字73618
访问http://www.heibanke.com/lesson/crawler_ex00/73618/
页面又提示要输入数字53825
访问http://www.heibanke.com/lesson/crawler_ex00/53825/
又提示要输入数字,于是推测这关要一直输入到某个数字后才能得到最后结果
那么我们可以将每个提示页面的数字,即下一个要输入的数字爬取下来,与原来的url构成一个下一个要访问的url,再继续爬取数字,假如爬取不到数字,就猜测可能得到了最后的结果
代码如下:
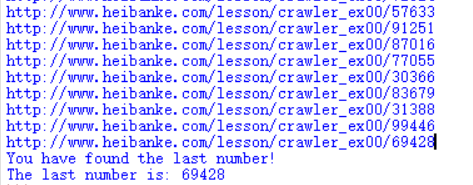
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import requestsimport reurl = 'http://www.heibanke.com/lesson/crawler_ex00/' num = '' while True : next_url = url+num print(next_url) r = requests.get(next_url) match = re.search(r'数字.*(\d{5})' ,r.text) if not match: print('You have found the last number!' ) print('The last number is:' ,str(num)) break num = match.group(1 )
这里通过正则匹配出下一个要输入的数字,然后与网页原本的url拼成下一个要访问的url,当匹配不到数字时退出循环
运行结果:
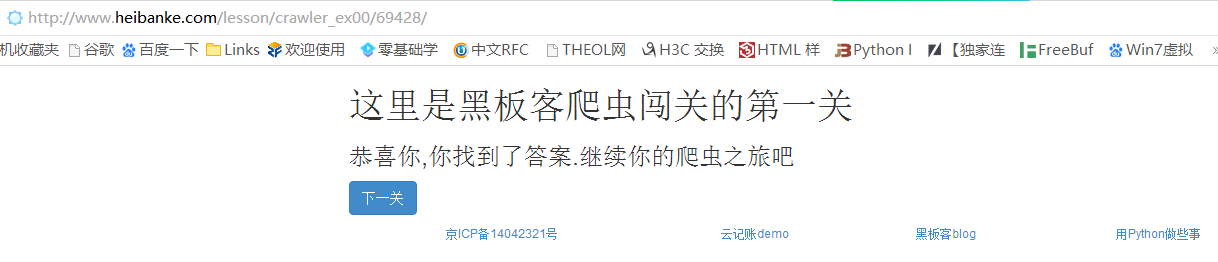
猜测69428是最后输入的数字,我们访问一下http://www.heibanke.com/lesson/crawler_ex00/69428/
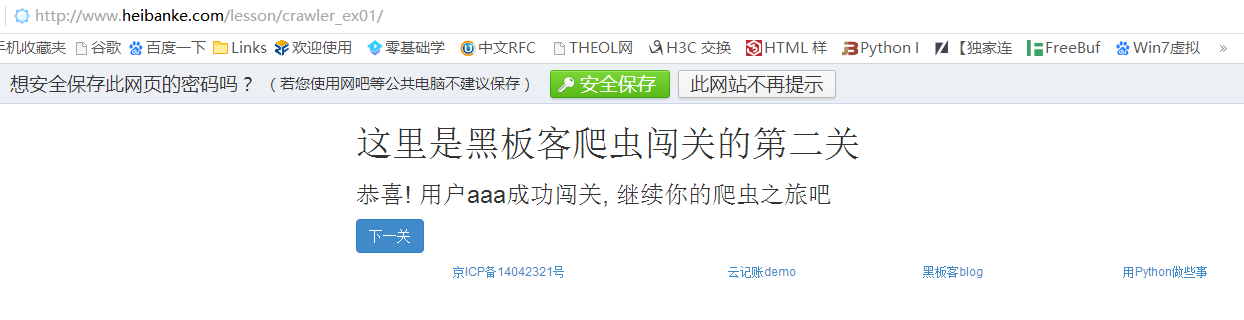
果然,页面提示了通关,点击下一关按钮,进入到第二关的页面
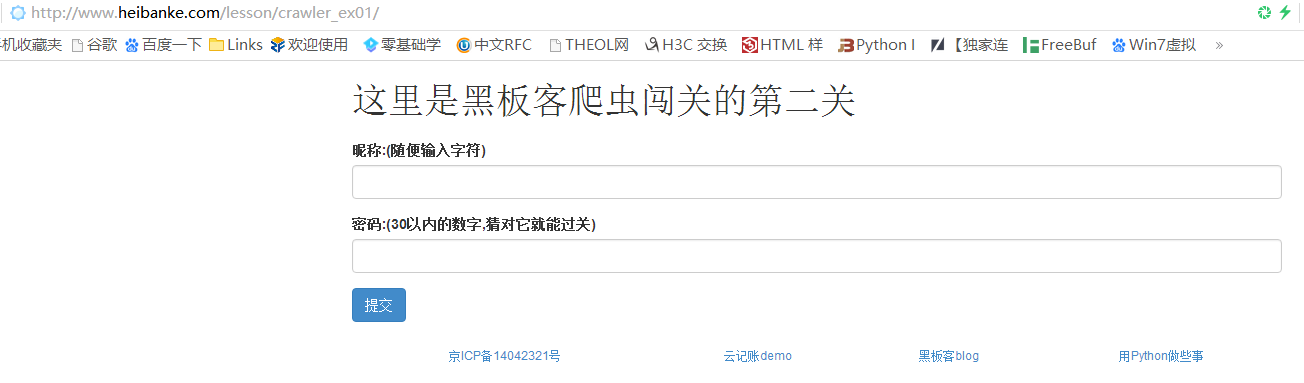
Pass-2 网址:http://www.heibanke.com/lesson/crawler_ex01/
首先根据页面提示,我们需要在表单中输入一个用户名和密码,用户名可以随机输入,密码则是1到30之间的数字
我们先来看一下源代码中的表单部分
可以看出表单是以POST形式提交的,提交的参数为username和password,还会提交一个隐藏的token值,看到token值,我们的第一反应都是要先获取到页面的token值,与数据一起提交,但是经过测试,这关后台服务器并没有对token值进行检测,也就是说我们在程序中并不需要提交这个token值,也可以提交成功,既然不用管token,那么这关就很简单了
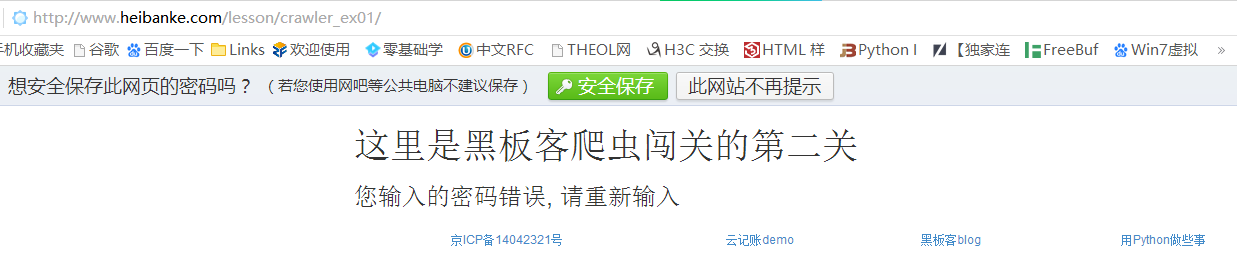
我们先随意提交一个用户名aaa和密码1看看提示是什么
可以看到页面提示”您输入的密码错误”,说明这是输入错误的提示信息,那么思路就很清晰了,我们依次提交数值为1-30之间的密码值,然后根据页面的提示信息是否包含”您输入的密码错误”,如果没有则可能是正确的密码
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import requestsurl = 'http://www.heibanke.com/lesson/crawler_ex01/' for i in range(1 ,31 ): data = { 'username' :'aaa' , 'password' :i, 'submit' :'提交' } r = requests.post(url,data=data) if '您输入的密码错误' not in r.text: print('Correct password:' ,str(i)) break else : print('Wrong password:' ,str(i))
运行结果:
说明20可能是正确的密码,我们在浏览器中提交
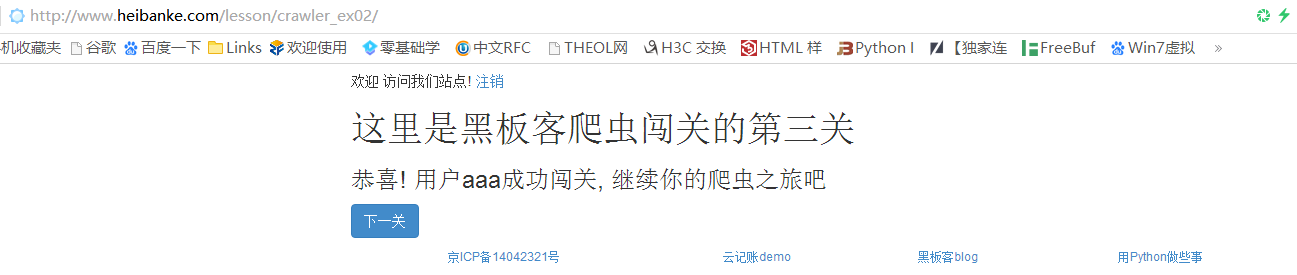
闯关成功,继续点击下一关按钮进入第三关
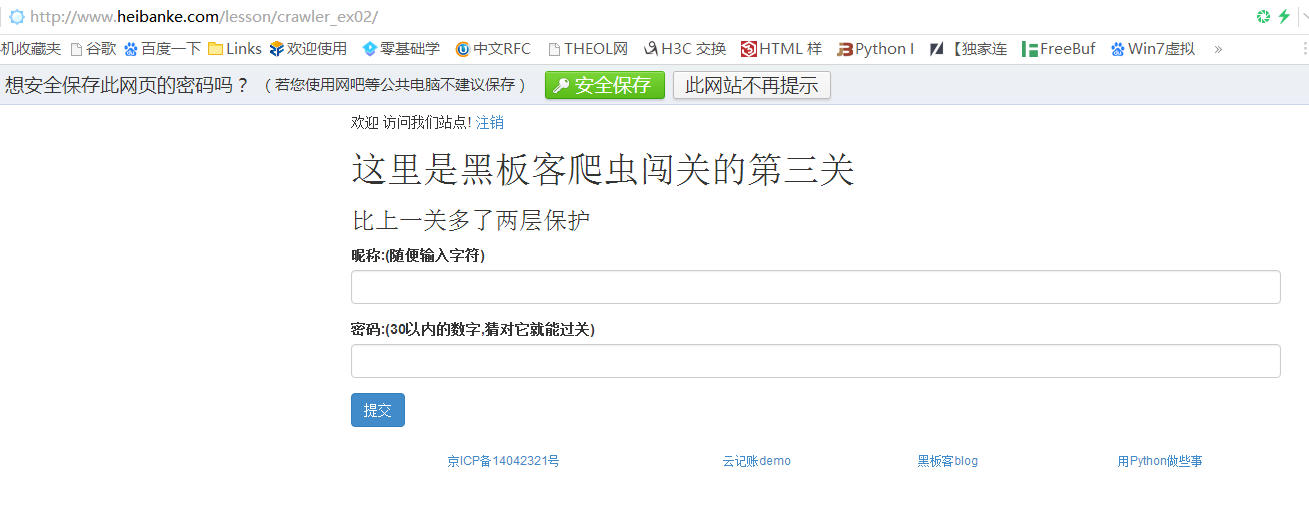
Pass-3 网址:http://www.heibanke.com/lesson/crawler_ex02/
我们会发现自动跳转到了登录页面,也就是说这一关需要模拟登录
我们先注册一个账号和密码登录进去
看起来和上一关没什么区别,一样是输入用户名和密码,用户名是随意的,密码还是1-30之间的数字,唯一区别在于页面提示比上一关多了两层保护,光看这句话还是很懵逼的,没事,我们看一看页面源代码,就可以大致猜到到底是什么保护了
可以看出表单提交了隐藏的token值,猜测这关服务器会对token值进行检测
再回到登录页面,查看源代码的表单部分
登录页面也有一个token值
所以思路是这样的,我们首先需要模拟登录,这就需要用到requests库的Session方法保持一个会话记录,否则我们再次访问这关的页面依旧会跳转到登录页面,然后我们还需要爬取页面信息的token值,也就是提交token的input标签的value值
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import requestsfrom bs4 import BeautifulSouplogin_url = 'http://www.heibanke.com/accounts/login/?next=/lesson/crawler_ex02/' pass_url = 'http://www.heibanke.com/lesson/crawler_ex02/' s = requests.Session() def getToken (html) : soup = BeautifulSoup(html,'html.parser' ) token = soup.find_all('input' )[0 ]['value' ] return token def login () : r = s.get(url=login_url) login_token = getToken(r.text) login_data = { 'csrfmiddlewaretoken' :login_token, 'username' :'xxx' , 'password' :'xxx' } login = s.post(url=login_url,data=login_data) if '这里是黑板客爬虫闯关的第三关' in login.text: print('login successfully!' ) pass_token = getToken(login.text) return pass_token pass_token = login() for i in range(31 ): data = { 'csrfmiddlewaretoken' :pass_token, 'username' :'aaa' , 'password' :i } result = s.post(url=pass_url,data=data) if '您输入的密码错误' not in result.text: print('------Correct password:' ,str(i)) break else : print('fail to pass' )
这里用了BeautifulSoup库的find_all方法获得所有input标签组成的列表,观察出token值所在的input标签是列表的第一个元素,就可以通过索引获得token值,登录成功后还要继续抓取关卡页面的token值,与用户名和密码一起提交
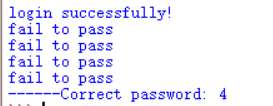
最后的运行结果如下:
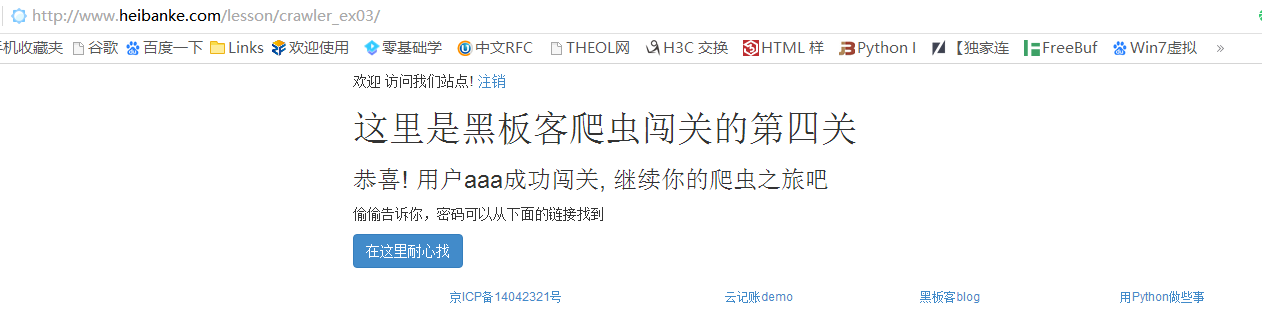
在浏览器中提交用户名:aaa,密码:4
闯关成功,此处后台代码有误,点击下一关还是第三关的页面,但是我们可以根据前面几关的url推测出第四关的url:http://www.heibanke.com/lesson/crawler_ex03/
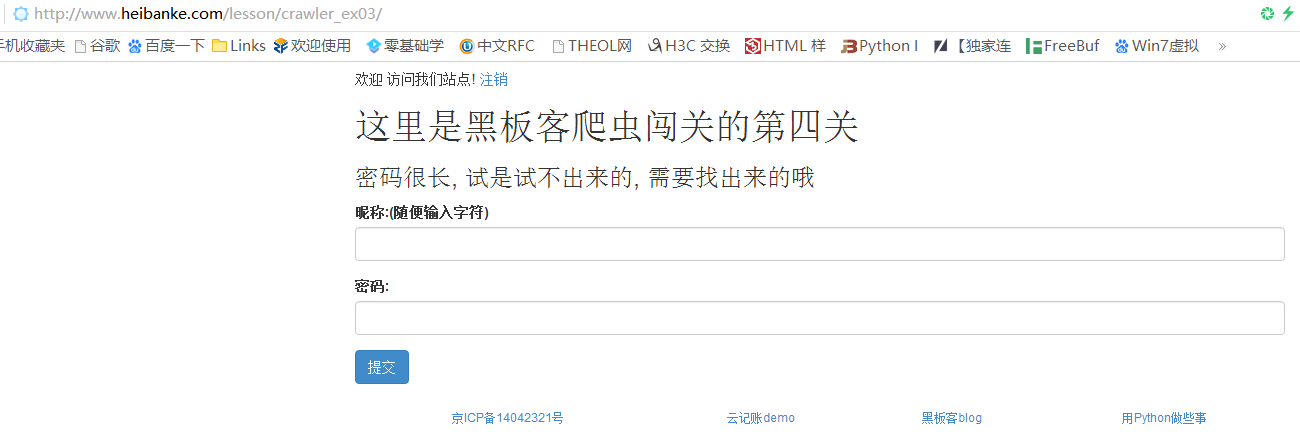
Pass-4 网址:http://www.heibanke.com/lesson/crawler_ex03/
跟第三关一样,还是需要先登录
登录后来到第四关关卡页面
页面提示”密码很长,是试不出来的,需要找出来”,看一下源代码,还是跟第二关第三关一样,提交username和password参数,服务器有对token值进行检测
但是还是没有关于密码的提示部分信息
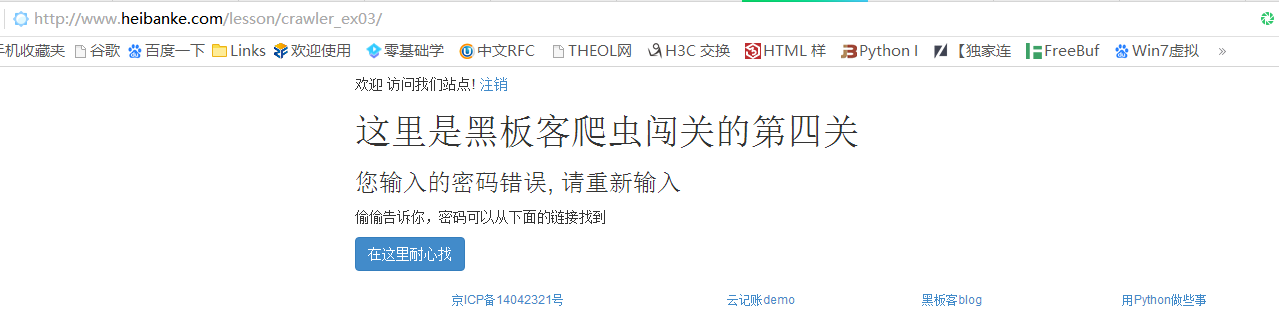
怎么办呢,我们先试一下随便输入一个密码1,看看页面返回什么
惊喜的发现提示来了,我们点击”在这里耐心找”访问到提示页面(PS:这个页面有点慢,需要耐心等待加载)
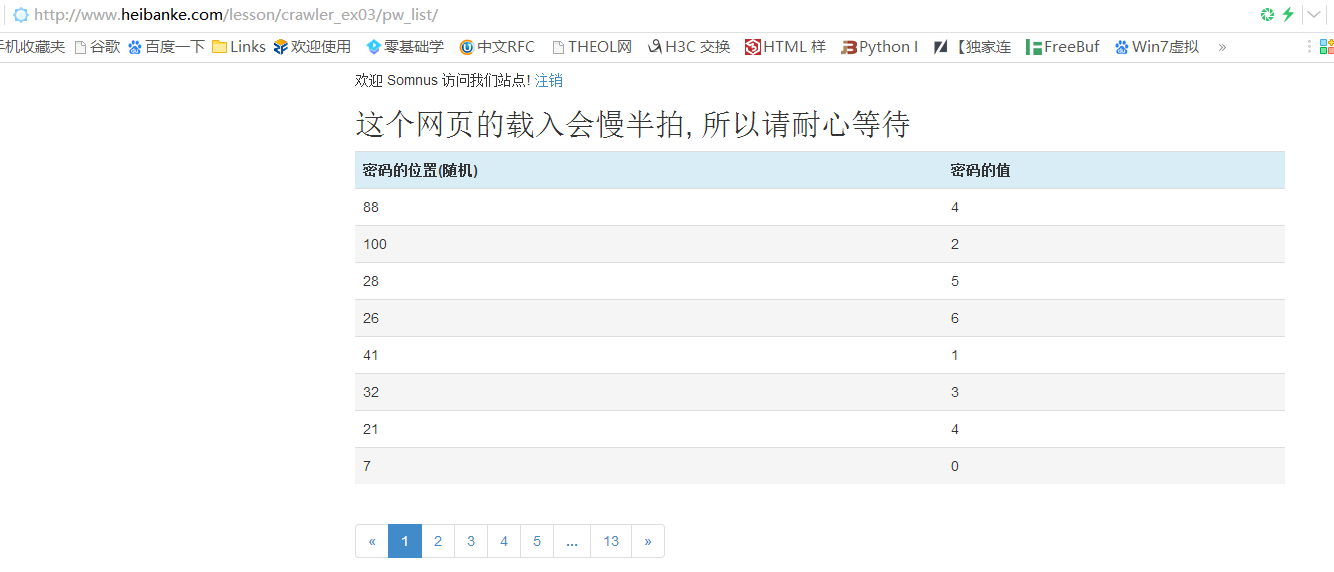
仔细观察,会发现这里提示信息是给出了一共100位的密码,其中每一位的值,而且每一页显示的位数还会变化,所以这里要访问所有的页数获取每一位数和对应的值是行不通的,所以我们干脆就一直访问第一页,爬取每一位的位数和对应的值,直到爬取位数共有100为止
直接附上代码吧:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import requestsimport refrom bs4 import BeautifulSouplogin_url = 'http://www.heibanke.com/accounts/login/?next=/lesson/crawler_ex03/' pass_url = 'http://www.heibanke.com/lesson/crawler_ex03/' hint_url = 'http://www.heibanke.com/lesson/crawler_ex03/pw_list/' s = requests.Session() def getToken (html) : soup = BeautifulSoup(html,'html.parser' ) token = soup.find_all('input' )[0 ]['value' ] return token def login () : r = s.get(login_url) login_token = getToken(r.text) login_data = { 'csrfmiddlewaretoken' :login_token, 'username' :'xxx' , 'password' :'xxx' } login = s.post(url=login_url,data=login_data) if '这里是黑板客爬虫闯关的第四关' in login.text: print('login successfully' ) pass_token = getToken(login.text) return pass_token def getDict () : total_pos = [] passwordDict = {} while True : hint = s.get(url=hint_url) pos = re.findall(r'title="password_pos">(\d*)' ,hint.text) value = re.findall(r'title="password_val">(\d*)' ,hint.text) for i in range(len(pos)): if pos[i] not in total_pos: total_pos.append(pos[i]) passwordDict[pos[i]] = value[i] if len(total_pos) == 100 : break else : print(len(total_pos)) print(passwordDict) return passwordDict def getPassword (dic) : passList = [] for i in range(1 ,101 ): passList.append(dic[str(i)]) password = '' .join(passList) return password pass_token = login() passwordDict = getDict() print(passwordDict) password = getPassword(passwordDict) print(password)
一开始还是跟第三关一样,先获取登录页面的token值,然后登录,页面如果有返回”这里是黑板客爬虫闯关的第四关”的信息说明登录成功,登录成功再获取关卡页面的token值,接下来就获取位置数和对应的值,这里定义了一个列表total_pos用来存放总的位置数和一个字典 passwordDict用来存放位置数及其对应的值,然后不断的访问提示页面的第一页,通过re模块的findall方法匹配出pos和value列表,每次匹配完检查pos列表的每一个元素,如果不在total_pos中,则添加进total_pos中,并将‘pos[i]’:’value[i]’键值对添加进字典中,直到匹配出100位为止,此时就获得了每一位和对应的值,再从第一位开始从字典中取出value值,添加进passList列表中,最后将passList列表元素拼成一个长字符串,就是最后获得的密码
这里过程实在是很慢,总之看脸…脸好很快就爬到了100位
最后获得的字典:
1 2 3 passwordDict = { '73' : '8' , '76' : '6' , '28' : '5' , '72' : '1' , '61' : '4' , '32' : '3' , '57' : '6' , '75' : '3' , '90' : '0' , '53' : '7' , '74' : '1' , '56' : '2' , '83' : '1' , '34' : '9' , '44' : '4' , '70' : '6' , '92' : '4' , '18' : '5' , '93' : '8' , '37' : '8' , '85' : '3' , '67' : '8' , '17' : '3' , '62' : '3' , '84' : '6' , '24' : '5' , '8' : '8' , '15' : '3' , '100' : '2' , '55' : '3' , '1' : '3' , '10' : '7' , '20' : '7' , '79' : '3' , '12' : '4' , '91' : '6' , '36' : '4' , '43' : '6' , '60' : '8' , '48' : '0' , '25' : '0' , '22' : '8' , '4' : '1' , '16' : '5' , '94' : '9' , '54' : '4' , '50' : '9' , '66' : '4' , '64' : '1' , '5' : '8' , '47' : '9' , '51' : '4' , '80' : '4' , '69' : '7' , '71' : '6' , '7' : '0' , '96' : '3' , '46' : '9' , '2' : '3' , '27' : '9' , '49' : '3' , '13' : '5' , '99' : '0' , '89' : '7' , '39' : '4' , '26' : '6' , '63' : '7' , '29' : '2' , '52' : '8' , '65' : '3' , '33' : '2' , '30' : '4' , '9' : '6' , '86' : '2' , '19' : '7' , '38' : '9' , '40' : '6' , '98' : '7' , '77' : '9' , '59' : '4' , '41' : '1' , '42' : '3' , '21' : '4' , '45' : '7' , '58' : '0' , '6' : '3' , '81' : '4' , '23' : '9' , '3' : '8' , '11' : '4' , '97' : '6' , '82' : '9' , '14' : '1' , '87' : '6' , '78' : '6' , '31' : '4' , '95' : '9' , '68' : '7' , '88' : '4' , '35' : '5' }
整理后的密码:
1 password = 3381830867445135357748950695244329548946136479903948743260484371348776618136963449163264706489936702
第五关的url依旧要靠猜
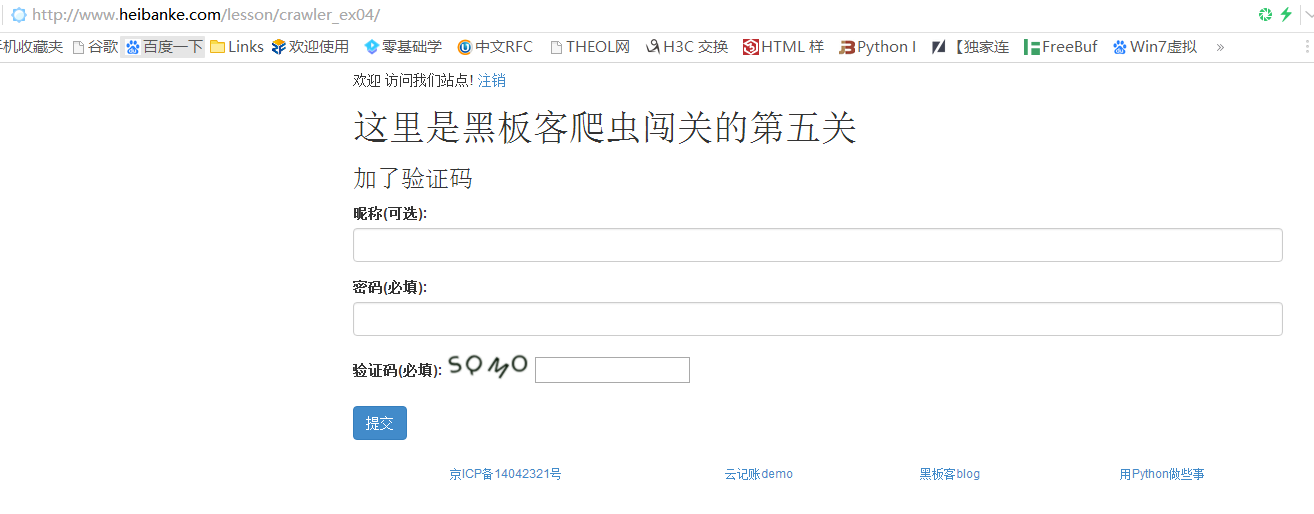
Pass-5 网址:http://www.heibanke.com/lesson/crawler_ex04/
依然要登录,很明显这关要提交验证码,观察一下源代码
可以发现这个验证码其实是一个url,点击进去能看到验证码的图片,跟token一样,每次刷新页面,验证码的url都会变化,因此验证码就会一直变化
所以,我们要通这最后一关,就必须要想办法获取这个验证码的值
在Python中,有一个库叫pytesseract,这个库里的image_to_string方法具有识别图片中信息的功能
由于这个库跟requests一样,是第三方库,因此我们需要先安装后才能使用
除了pytesseract库之外,我们还依赖PIL库的Image方法打开一个图片
安装这两个库都可以用pip命令安装
比较关键的是pytesseract库识别验证码还依赖于一个插件Tesseract-OCR ,这个插件我们可以百度搜索tesseract-ocr-setup-3.02.02.exe 下载,这里我使用的是3.02版本,没有碰到什么问题,按照安装提示一步步下载下来,唯一要注意的是要按照默认路径下载,Windows的默认安装路径是C:\Program Files (x86)\Tesseract-OCR\
这是因为我们下载完后需要在Python文件夹的下的\Lib\site-packages\pytesseract\pytesseract.py修改源代码中
1 tesseract_cmd = 'tesseract'
修改为:
1 tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract.exe'
安装完成后,我们就可以获取验证码了,除了验证码外,我们还要获取三个值:登录界面的token值,关卡界面的token值,关卡界面的captcha_1 值
需要注意的是,我们用pytesseract库虽然可以识别验证码,但并不是百分百正确,所以我们需要对验证码进行校验,经过观察本关的验证码都是四个大小写英文字母,我们可以通过正则匹配进行校验,如果校验失败,则继续识别,直到校验成功,则提交猜测的密码,这里密码从0开始递增猜测
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 import requestsimport pytesseractimport refrom bs4 import BeautifulSoupfrom PIL import Imagefrom io import BytesIOlogin_url = 'http://www.heibanke.com/accounts/login/?next=/lesson/crawler_ex04/' pass_url = 'http://www.heibanke.com/lesson/crawler_ex04/' s = requests.Session() def getToken (html) : soup = BeautifulSoup(html,'html.parser' ) token = soup.find_all('input' )[0 ]['value' ] return token def getCaptcha_0 (html) : soup = BeautifulSoup(html,'html.parser' ) Captcha_0 = soup.find('input' ,id="id_captcha_0" )['value' ] return Captcha_0 def login () : r = s.get(url=login_url) login_token = getToken(r.text) login_data = { 'csrfmiddlewaretoken' :login_token, 'username' :'xxx' , 'password' :'xxx' } login = s.post(url=login_url,data=login_data) if '这里是黑板客爬虫闯关的第五关' in login.text: print('login successfully!' ) def getImageURL (html) : soup = BeautifulSoup(html,'html.parser' ) imageURL = 'http://www.heibanke.com' +soup.find('img' ,class_='captcha' )['src' ] return imageURL def getImageCode () : while True : print('--------------------开始识别验证码' ) pas = s.get(url=pass_url) imageURL = getImageURL(pas.text) image = s.get(url=imageURL) captcha_img = Image.open(BytesIO(image.content)) imageCode = pytesseract.image_to_string(captcha_img) print('验证码识别结果:' ,imageCode) print('--------------------开始校验验证码' ) match = re.search(r'^[A-Z | a-z]{4}$' ,imageCode) if not match: print('验证码:' ,imageCode,'校验结果识别失败,继续识别' ) else : print('验证码:' ,imageCode,'校验成功' ) mess = (imageCode,pas) break return mess def guess () : password = 0 while True : print('--------------------------------------开始猜测密码' ) imageCode,pas = getImageCode() pas_token = getToken(pas.text) Captcha_0 = getCaptcha_0(pas.text) data = { 'csrfmiddlewaretoken' :pas_token, 'username' :'aaa' , 'password' :password, 'captcha_0' :Captcha_0, 'captcha_1' :imageCode } g = s.post(url=pass_url,data=data) if '验证码输入错误' in g.text: print('验证码输入错误' ) elif '您输入的密码错误' in g.text: print('密码:' ,password,'错误' ) password +=1 else : print('密码:' ,password,'正确' ) print('返回的页面结果:' ) print(g.text) break login() guess()
这关坑还是很多的,主要是识别校验码的正确率有点低,即使校验结果是四个英文字母,也不一定是正确的验证码,而且密码是随着时间变化的,总之耐心尝试吧,有了思路多尝试最后总是能成功的
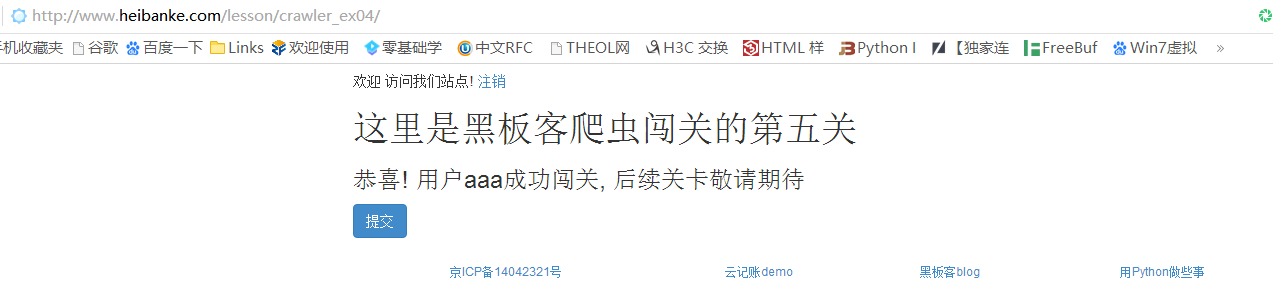
最后我的时间段检测到的正确密码:
在浏览器提交密码19
最后附上参考的链接:https://www.jianshu.com/p/f64853b8f7e9